





在当今这个数据驱动的时代,数据的质量和完整性直接关系到决策的准确性和效率,在数据收集和分析的过程中,如何确保“不分遗漏”地选择数据,成为了一个至关重要的挑战,本文将深入探讨这一主题,从定义“不分遗漏数据”的必要性、常见的数据遗漏原因、到如何实施有效的数据收集策略,旨在为读者提供一套系统性的解决方案。
一、定义“不分遗漏数据”的必要性
“不分遗漏数据”是指在数据收集和分析过程中,确保所有相关、有价值的信息都被纳入考虑,没有遗漏或偏见,这一原则的必要性体现在以下几个方面:
1、决策的准确性:遗漏关键数据可能导致决策失误,影响企业或项目的长远发展。
2、资源浪费:不完整的数据可能导致资源的不合理分配,造成不必要的浪费。
3、信任与透明度:数据的完整性和透明度是建立信任的基础,对于企业形象和客户信任至关重要。
4、持续改进:只有通过全面分析数据,才能发现改进的契机,推动持续优化和创新。
二、常见的数据遗漏原因
要实现“不分遗漏数据”,首先需要了解可能导致数据遗漏的常见原因:
1、样本偏差:选择不具代表性的样本或仅基于特定群体进行调查,导致结果失真。
2、数据采集工具限制:技术或工具的局限性可能限制了数据的收集范围和深度。
3、人为错误:数据处理过程中的疏忽、误解或故意隐瞒可能导致数据遗漏。
4、数据清洗与预处理:在数据清洗和预处理阶段,如果方法不当或过于激进,可能会误删有价值的信息。
5、时间与资源限制:由于时间、预算或技术资源的限制,可能无法收集到所有期望的数据。
三、实施有效的数据收集策略
为了确保“不分遗漏数据”,以下是一些有效的数据收集策略:

1、多元化数据源:
- 结合多种数据源(如官方统计、社交媒体、用户反馈等),以增加数据的广度和深度。
- 考虑使用不同的调查方法(如问卷调查、访谈、观察等),以减少单一方法带来的偏差。
2、全面性设计:
- 在设计调查问卷或实验时,采用“全面覆盖”原则,确保所有相关问题都被纳入考虑。
- 避免先入为主的假设,保持开放性的问题设计,以捕捉意外但重要的信息。
3、技术辅助与自动化:
- 利用现代技术(如大数据分析、机器学习)来自动识别和收集数据,减少人为错误。
- 实施自动化监控和警报系统,及时发现并解决潜在的数据遗漏问题。
4、严格的数据清洗与预处理:
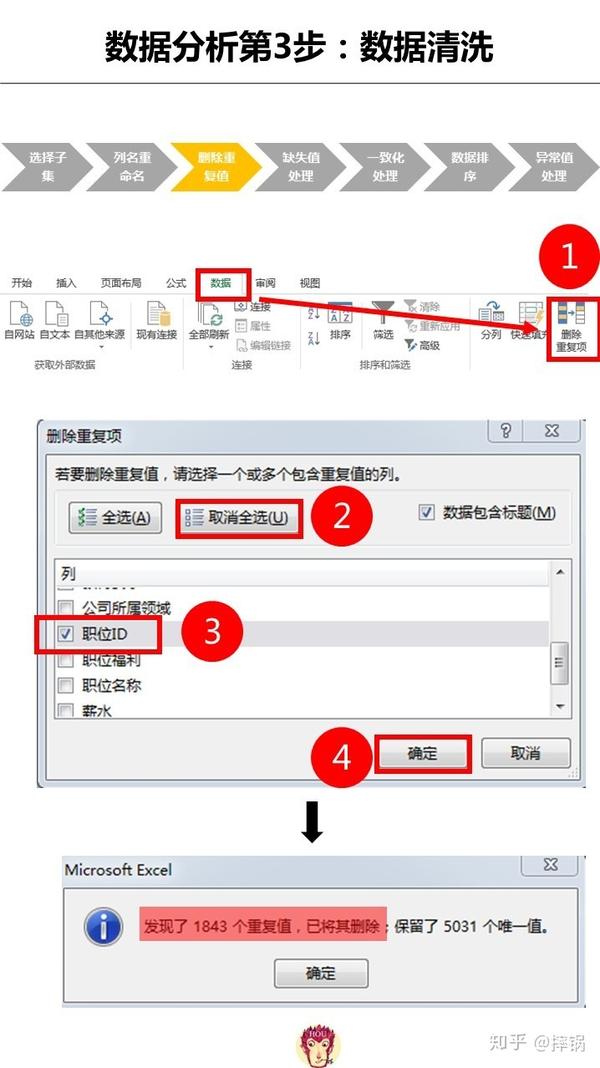
- 在数据清洗阶段,采用严格但灵活的规则,避免误删有价值的信息。
- 实施多轮审核和校验机制,确保数据的准确性和完整性。
5、持续监控与反馈:
- 设立定期的数据质量检查机制,及时发现并解决遗漏问题。
- 鼓励团队成员之间的反馈和交流,共同提升数据收集的全面性。
6、培训与教育:
- 对团队成员进行数据收集和分析的培训,提高其识别和避免数据遗漏的能力。
- 强调数据的完整性和透明度在决策中的重要性,培养团队的整体意识。
四、案例分析:如何在实际操作中应用“不分遗漏数据”原则
以某电商平台的数据分析为例,该平台希望通过分析用户行为来优化产品推荐系统,为了确保“不分遗漏数据”,他们采取了以下措施:
1、多元化数据源:除了内部日志和交易记录外,还从社交媒体上收集用户评论和讨论,以及通过问卷调查了解用户偏好和需求变化。
2、全面性设计:在用户行为分析中,不仅关注购买行为,还考虑了浏览行为、搜索历史、用户反馈等多个维度,通过设计全面的问卷和算法模型,捕捉用户的隐含需求和潜在问题。
3、技术辅助与自动化:利用大数据分析工具进行实时监控和预警,及时发现异常或遗漏的数据点;同时通过机器学习模型自动识别并补充缺失信息。
4、严格的数据清洗与预处理:在数据清洗阶段采用多轮审核机制,确保数据的准确性和完整性;同时利用自然语言处理技术从用户评论中提取有价值的信息。
5、持续监控与反馈:设立定期的数据质量检查会议,邀请团队成员共同参与讨论和分析;同时鼓励用户反馈机制,及时调整和优化推荐系统。
6、培训与教育:定期对团队成员进行数据分析培训,提高其识别和避免数据遗漏的能力;同时强调数据的完整性和透明度在产品优化中的重要性。
通过这些措施的实施,该电商平台成功提高了用户满意度和产品推荐系统的准确性,实现了“不分遗漏数据”的目标。





 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...